We are excited to announce the release of the Databricks AI Security Framework (DASF) Agentic AI Extension whitepaper! Databricks customers are already deploying AI agents that query databases, call external APIs, execute code, and coordinate with other agents. We constantly hear the teams responsible for those deployments are asking hard questions: what happens when the AI can _do_ things, not just _say_ things? That is why we have extended DASF.
With this update, we introduce new guidance for securing autonomous AI agents:
* 35 new agentic AI security risks covering agent reasoning, memory, and tool usage * 6 new mitigation controls including least privilege, sandboxing, and human oversight * Security guidance for Model Context Protocol (MCP) tool servers and clients * Coverage for multi-agent system risks and agent communication threats
Together these additions help organizations deploy AI agents safely while maintaining governance, observability, and defense-in-depth security controls.
This brings the full framework to 97 risks and 73 controls. We have updated the DASF compendium (Google sheet, Excel) to include these new risks and controls, mapping them to industry standards to facilitate immediate operationalization. These additions are cataloged as DASF v3.0 under the "DASF Revision" column. 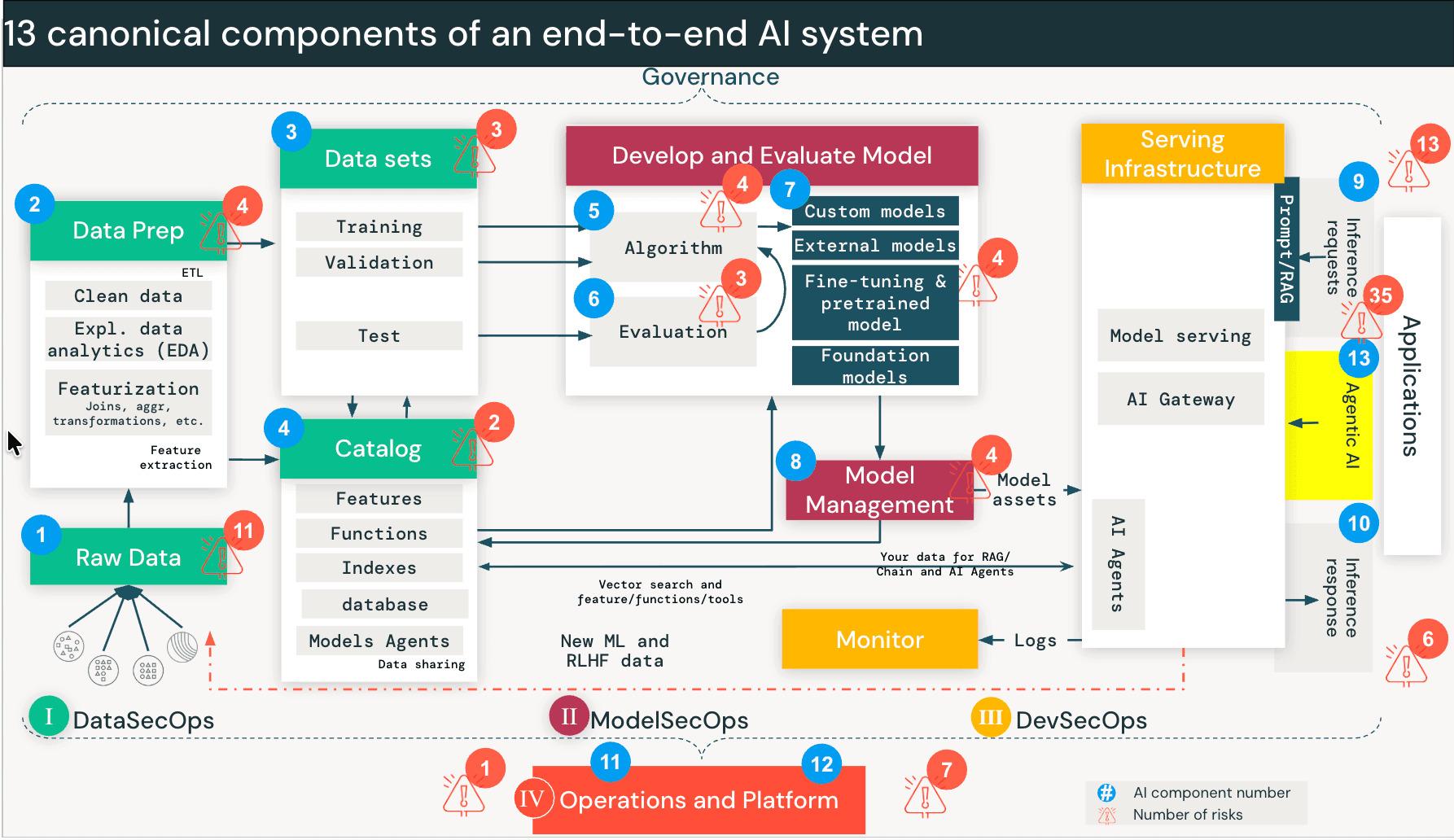 Fig 1: The 13 canonical components of an end-to-end AI system, with Agentic AI introduced as the 13th component.
Security risks when AI agents can take actions
Traditional AI systems like RAG operate mostly in a read-only mode. But AI agents can take actions such as querying databases, calling APIs, executing code, and interacting with external tools.
Agents work differently. When a user engages an agent, the model kicks off a loop: it breaks the request into sub-tasks, picks a tool (say, "Query Sales Database"), executes it, evaluates the output, and decides whether to call a different tool next. This continues until the task is done. The agent is making real-time decisions about which data to access and which tools to invoke — decisions that used to be made by humans or hardcoded into application logic.
That creates a new class of risk we call Discovery and Traversal. An agent designed to find solutions will traverse data paths and tool interfaces that were never intended for the requesting user. It's not exploiting a bug. It's doing exactly what it was built to do. But without proper controls, the user effectively inherits the agent's permissions rather than their own. The Lethal Trifecta. Recent industry research, including Meta’s “Agents Rule of Two” and similar models like Simon Willison’s “Lethal Trifecta”, highlights the conditions under which this gets dangerous. The risk profile spikes when three conditions are present simultaneously:
- Access to sensitive systems or private data: The agent can retrieve private or restricted data.
- Process untrustworthy inputs: The agent processes data from outside the trust boundary — user prompts, external websites, incoming emails.
- Change state or communicate externally: The agent can modify state through tools or MCP connections — sending emails, executing SQL, modifying code.
How the extension is organized
The 35 new risks and 6 controls are organized around three sub-components that map to how agents actually work:
13A: The Agent Core (brain and memory)
These risks target the agent's reasoning loop. Memory Poisoning (Risk 13.1)introduces false context that alters current or future decisions. Intent Breaking & Goal Manipulation (Risk 13.6) coerces the agent into deviating from its objective. And because agents operate in multi-turn loops, Cascading Hallucination Attacks (Risk 13.5) can compound a minor error across iterations into a destructive action.
13B: MCP Server risks (the tool interface)
Agents interact with external systems through tools, increasingly standardized via the Model Context Protocol (MCP). On the server side, attackers may deploy Tool Poisoning (Risk 13.18) — injecting malicious behavior into tool definitions — or exploit Prompt Injection (Risk 13.16) within tool descriptions to bypass security controls.
13C: MCP Client risks (the connection layer)
On the client side, if the agent connects to a Malicious Server (Risk 13.26) or fails to validate server responses, it risks Client-Side Code Execution (Risk 13.32) or Data Leakage (Risk 13.30). As MCP adoption grows, securing the client-server boundary matters as much as securing the agent's reasoning.
Inter-agent dynamics
Agents will increasingly communicate with other agents. That creates risks of Agent Communication Poisoning (Risk 13.12) and Rogue Agents in Multi-Agent Systems (Risk 13.13) — agents that operate outside monitoring boundaries, a problem that compounds with scale.